

Featured Projects
Learning Directed Operating System NSF Expedition in Computing
The Learning Directed Operating System (LDOS) Expedition is a $12-million NSF Expedition in Computing (2024-2029) developing a next-generation, machine learning-based, self-adaptive Operating System that efficiently supports modern applications in dynamic, complex computing environments.

Transformative Use Cases
Our project aims to show the transformative real-world impact of LDOS via three compelling use cases:
Autonomous Mobile Service Robots that concurrently run novel 3rd party apps extending the robot's core functionality.
Self-Managing Clouds that achieve high dependability and high utilization.
Real-time 6G Mobile Access Edges that enable novel real-time edge applications.
Individual Projects
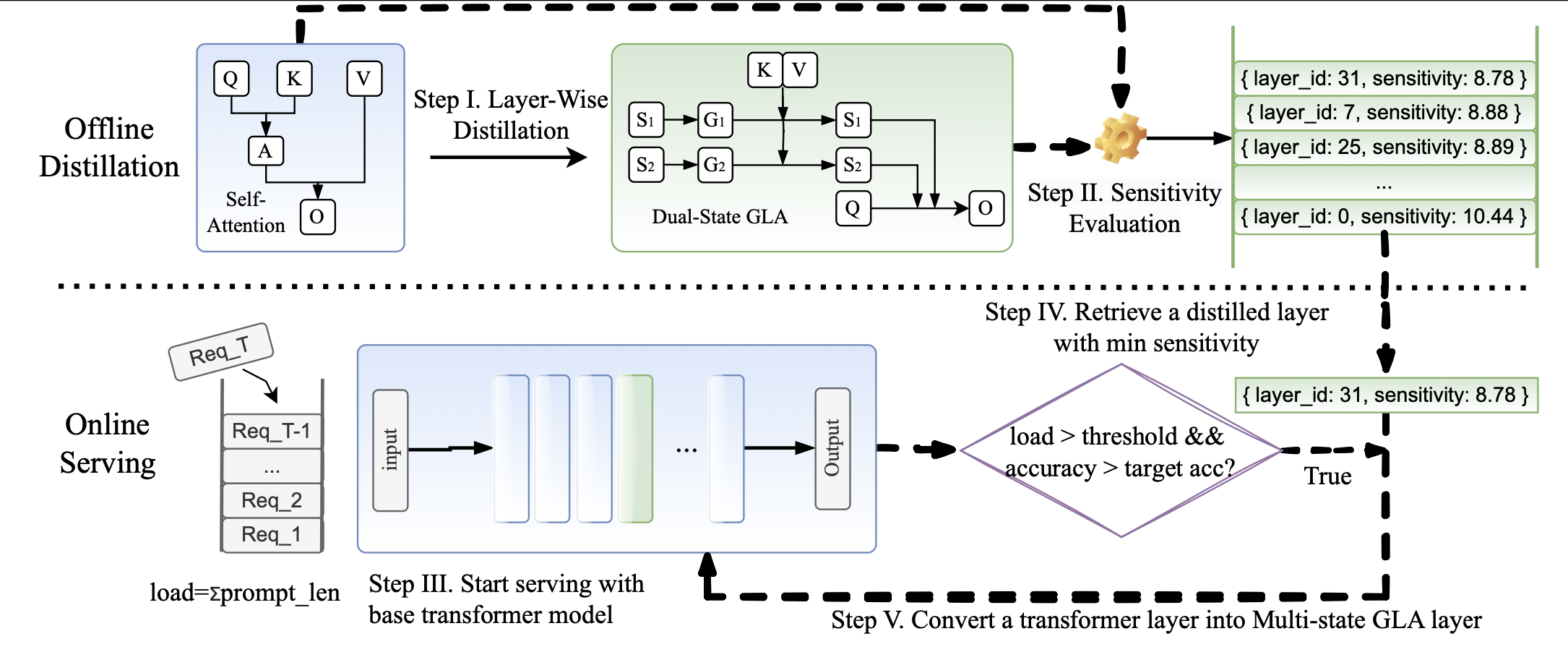
Yeonju Ro, Zhenyu Zhang, Souvik Kundu, Zhangyang Wang, and Aditya Akella
An adaptive LLM serving system that dynamically replaces self-attention layers with linear-time counterparts to achieve much faster and efficient long-context LLM serving under high-load scenarios.

Geon-Woo Kim, Junbo Li, Shashidhar Gandham, Omar Baldonado, Adithya Gangidi, Pavan Balaji, Zhangyang Wang, and Aditya Akella
A hierarchical method to pretrain LLMs on multi-region clusters, introducing (1) local regional parameter servers that exclusively communicate with local workers in the same region using fast intra-region comms and (2) a global parameter server orchestrates learning progresses across multiple regions.
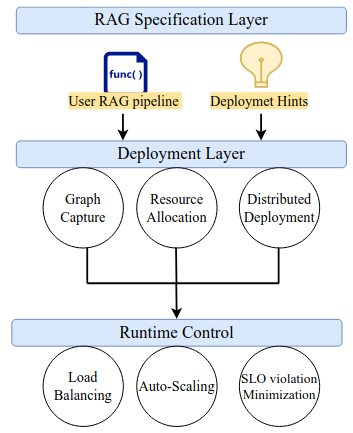
Bodun Hu, Luis Pabon, Saurabh Agarwal, and Aditya Akella
Patchwork delivers an end-to-end framework for serving Retrieval-Augmented Generation (RAG) applications. At its core is a flexible specification layer that lets users define workflows in the framework of their choice. An orchestration layer then brings these workflows to life—intelligently allocating resources and handling distributed deployment. On top of this, a runtime controller ensures seamless configuration and management during execution. With Patchwork, building a RAG application is as simple as writing Python control flow—while the system automatically scales it into a fully distributed deployment.

Saurabh Agarwal, Anyong Mao, Aditya Akella, and Shivaram Venkataraman
We introduce a disaggregated memory layer that allows large language models (LLMs) to offload internal state into far memory, unlocking more efficient utilization of GPU compute. To mitigate the latency overhead of disaggregation, Symphony leverages workload-specific hints that naturally arise across a wide range of LLM tasks.
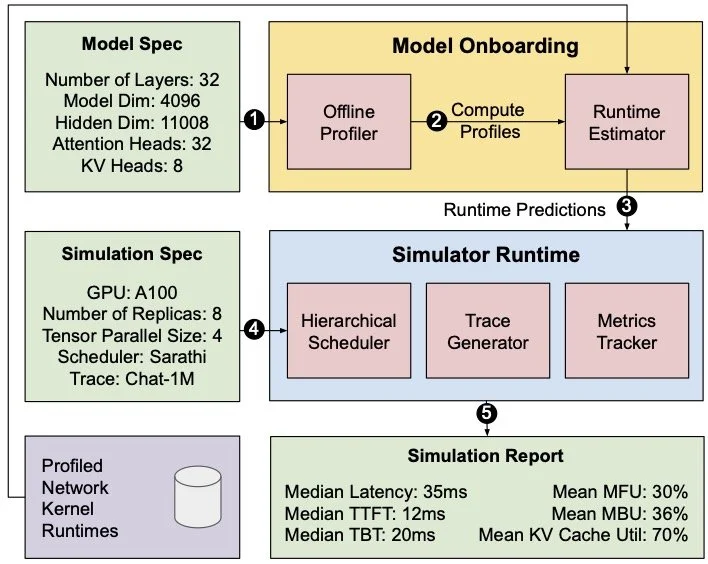
Amey Agrawal, Nitin Kedia, Jayashree Mohan, Ashish Panwar, Nipun Kwatra, Bhargav S. Gulavani, Ramachandran Ramjee, and Alexey Tumanov
Vidur is a fast, accurate, and extensible LLM inference system simulator. With it you can: 1. Find the serving performance (TTFT, TPOT, Memory utilization e.t.c.) of many LLMs (e.g. LLaMA-3, Mistral) for your own workload deployed on different GPUs (H100, A100), 2. Quickly test new research ideas such as new scheduling algorithms (e.g. routing, batching algorithm) – all without access to GPUs except for a quick initial profiling phase. Each simulation runs on a single CPU core and can process a thousand requests under a minute. This is enabled by a full-stack implementation of an actual serving engine (Sarathi-Serve and vLLM) with the forward pass replaced by an accurate batch time estimator.